Spielzeug genau nach meinem Geschmack: Regex Crossword ist ein Spiel bei dem horizontal und vertikal durch reguläre Ausdrücke angegeben wird mit welchen Buchstaben die Felder ausgefüllt werden müssen. Schöne Idee, und gut umgesetzt. 
Kategorie: Software
Texte mit Bezug auf Software
Terminal Multiplexer: screen / byobu ➜ tmux

tmux in der Praxis
Was im Web-Browser die Tabs sind ist in der Shell der Terminal Multiplexer. Ich brauche nicht mehrere Fenster zu öffnen, ich kann einfach mehrere Anwendungen in einem Fenster ‚fahren‘. Beim Betrieb auf einem Server kommt noch der Komfort dazu, dass ich mich am Multiplexer an- und abmelden kann wie ich will, die Anwendungen laufen einfach weiter. So habe ich meinen Mail- und Chat-Client auf einem Server laufen, dann muss ich mich nicht immer an IRC & Co. anmelden wenn ich online gehe, und ich habe immer die Backlogs die ich bei Interesse überfliegen kann.
Jahrelang war ich mit GNU Screen sehr zufrieden. Ich hatte mir da eine nette Statuszeile gebastelt die mir sagt welche ‚Fenster‘ ich habe, zusätzlich wurden mit einem kleinen Perlskript ein paar Infos eingeblendet: IP-Adresse, System Load, Akkustatus und dergleichen.
Auf meinem neuen Firmennotebook habe ich Byobu gefunden. Das ist eine Art vorkonfiguriertes Screen (dachte ich zumindest) das ab Werk ganz ähnlich aussieht wie meine angepasste Variante. Über Tastendruck kann man da eine Menge konfigurieren, alles in allem eine nette Sache. Irgendwann wollte ich die Infos in der Statuszeile aber anpassen. Genau genommen wollte ich einen Eintrag haben der mir den aktuellen Status aus meinem Zabbix anzeigt. Also habe ich mir angesehen wie Byobu aufgebaut ist.
Zu meiner Überraschung lag da gar kein Screen drunter. Kann man auch machen, per Default nutzt Ubuntu aber tmux. Darüber hatte ich schon viel gutes gelesen, konnte mich aber doch irgendwie nicht von meinem gewohnten Screen trennen. Da ich aber unwissend mehrere Monate mit tmux zufrieden war habe ich das dann doch noch mal überdacht, und was soll ich sagen? Ich bin begeistert!
Ich habe mir wieder ein Skript gebastelt das für die Statusleiste interessante Daten zusammenklaubt, diesmal in Python. Und ich habe mir angeeignet wie man mit aufgeteilten Fenstern arbeitet. Das geht zwar auch im Screen, aber im tmux macht es dagegen wirklich Spaß, und das ist einer der größten Vorteile.
Wenn ich was für den Mikrocontroller entwickle habe ich oben einen großen Vim mit dem Code, unten links kann ich in einer kleinen Shell Kommandos absetzen — compilieren und flashen beispielsweise, und unten rechts sehe ich Debug-Ausgaben vom Controller.
Oder ich habe auf einem anderen Schirm groß meinen Mailclient. Unten sind drei Zeilen meines Chatclients zu sehen, wenn da eine interessante Aktivität angezeigt wird kann ich auf Tastendruck wechseln. Der Chat wird dann oben groß, und der Mailclient ist unten in den drei Zeilen zu sehen.
Ich bin sehr zufrieden damit, und ich ärgere mich dass ich nicht schon wesentlich eher umgestiegen bin…
Neue Kategorie: Tool-Time
Ich habe dem Blog eine neue Kategorie verpasst: unter Tool-Time möchte ich in Zukunft Teile meines Werkzeugkastens vorstellen. Damit meine ich nicht unbedingt physisches Werkzeug — Hammer, Schraubenschlüssel & Co. — sondern insbesondere Software.
Vor einiger Zeit habe ich den Arbeitgeber gewechselt. Auf meinem letzten Arbeitsplatzrechner hatte ich — genau wie zu Hause — Arch Linux. Leider konnte ich den aber bei meinem letzten Kunden nicht benutzen, da ich da mit dem Kundenrechner arbeiten musste. Den Kunden bin ich jetzt genau wie den Arbeitgeber los, auch das alte Notebook habe ich nicht mehr.
Von Arch bin ich zwar immer noch sehr angetan, um bei meinem neuen Arbeitgeber aber schnell ‚an die Schüppe‘ zu kommen habe ich das von Dell vorinstallierte Ubuntu auf dem Notebook gelassen.
Da bin ich dann erstmal mit den Standardwerkzeugen gefahren. Klar habe ich ein paar (für mich) unverzichtbare Werkzeuge installiert, aber ich habe weder meine Konfiguration von zu Hause mitgebracht, noch ähnlich viel Sorgfalt auf die Feineinstellung aufgewandt. Vor ein paar Wochen hat es mich dann aber doch gepackt, und seitdem konvergieren die beiden Welten. Ich habe eine Menge Konfiguration von zu Hause übernommen, aber auch einige völlig neue Tools für mich entdeckt. Irgendwie bin ich dann angefangen fast meinen kompletten Werkzeugkasten in Frage zu stellen, und ich muss sagen: das Ergebnis gefällt mir. 
Nachdem auf dem Computer die meisten Werkzeuge optimiert waren fiel dann mein Blick auf mein altgedientes HTC Desire… und auch das kommt Heute mit einer komplett anderen Ausstattung daher als noch vor vier Wochen. An der Stelle gebe ich zu dass ich immer noch auf ein Nexus 4 schiele, aber mit der neuen Software gefällt mir eigentlich auch der alte Fernsprecher noch ganz gut…
Langer Rede kurzer Sinn: hier ist die neue Kategorie, und hier gilt noch mehr als in den anderen Kategorien: ich freue mich über jede Rückmeldung! Nichts Fast nichts ist so gut dass man es nicht noch verbessern könnte… 
OpenVMS ist nicht mehr
Schade. VMS ist sicher eines der interessanteren Betriebssysteme. Habe ich leider nie persönlich kennenlernen dürfen, aber ich wäre mit Eifer dabei gewesen. Jetzt gehen die Chancen gegen Null, das nochmal zu Gesicht zu bekommen: HP hat die Entwicklung eingestellt. 
Angriffe auf WordPress
In den letzten Wochen hat es mehrfach Meldungen gegeben nach denen Betreiber von Blogs auf der Basis von WordPress vorsichtig sein sollten. Zur Zeit sind offenbar irgendwelche Botnetze darauf aus, sich per Brute Force an fremden Systemen anzumelden.
Ich habe mir um das zu unterbinden das Plugin Limit Login Attempts installiert, und zumindest bis jetzt tut es exakt was ich davon erwarte: kommen von einer IP zu viele fehlgeschlagene Anmeldeversuche, wird sie für einen gewissen Zeitraum komplett von der Anmeldung ausgeschlossen. Die Parameter — wie viele Fehlversuche sind erlaubt, wann darf sich die IP wieder melden, wann werden Fehlversuche zurückgesetzt — sind dabei ziemlich frei konfigurierbar, und bei jeder Sperrung bekomme ich eine Mail mit ein paar Infos.
Bislang war da noch nicht viel, aber Heute hat eine Welle diesen Blog erfasst. Auch die ist noch harmlos, das geht schlimmer. Aber im Laufe des Nachmittags haben mehr als 50 verschiedene IPs versucht, sich hier anzumelden. Alle übrigens als ‚admin‘, ‚administrator‘ oder ‚adminadmin‘ — Namen die man seinen Benutzern also tunlichst nicht geben sollte. Wer noch den Standardaccount in seiner Installation hat darf sich also schnell ins Backend aufmachen und den löschen… besser ist das.
Update-Dschungel: apt-get upgrade?
Interessant: vor einiger Zeit habe ich mit einem damaligen Kollegen darüber gesprochen dass ich es unzumutbar kompliziert finde, ein Windows-System aktuell zu halten. Dabei bedeutet ‚aktuell‘ nicht nur dass man die neuesten Features nutzen kann, sondern insbesondere auch dass Sicherheitslöcher — die es heutzutage sogar in MP3-Abspielern und PDF-Betrachtern geben kann — gestopft werden.
Leider erwähnt es der Artikel nicht den Heise Gestern zu dem Thema veröffentlicht hat, daher schreibe ich es nochmal (falls der ehemalige Kollege oder sonstwer aus der Zielgruppe mitliest): Wo Windows-Anwender im Schnitt an 25 Stellen (die Zahl nennt der Artikel, die stammt offenbar von Secunia) nach Updates suchen müssen greifen Linux-Benutzer üblicherweise nur auf einem einzigen Weg auf ihre Software-Repositories zu. Debian-Benutzer geben beispielsweise nur apt-get update && apt-get upgrade ein und können sich sicher sein die letzten Pakete installiert zu haben die ihre Distribution ihnen bietet. Fertig. Grafische Benutzeroberflächen, insbesondere auf Mainstream-Systemen wie Ubuntu, bringen die Funktionalität grafisch. Da muss man weder selbst an den Check denken, noch das Kommando für das Update auswendig gelernt haben.
Insbesondere bei Sicherheitsrelevanten Updates sind eigentlich alle gängigen Linuxe ziemlich schnell. Ich persönlich habe ein gutes Gefühl bei der Sache.
Zwei Einwände hatte der Kollege seinerzeit noch:
- Was ist mit Programmen die nicht von der Distribution gestellt werden? — Brot- und Butterprogramme wie Webbrowser, Office-Pakete oder Java-Laufzeitumgebungen bieten alle Distributionen. Braucht man eine spezielle Software findet man mit etwas Glück ein spezialisiertes Repository das man einfach einbinden kann. Gibt es auch das nicht bleibt einem wirklich nur die manuelle Installation. In dem Fall muss man aber nur ein einzelnes Programm manuell aktuell halten. Nicht alle (OK, fast alle). Wenn man mehrere Rechner versorgen will, beispielsweise in Unternehmen, spricht aber auch nichts dagegen sich ein eigenes Repo anzulegen. Schwer ist das nicht.
- Datenschutz? Ist Dir egal dass $DISTRIBUTOR weiß was Du alles installiert hast? — Ja. Weil ich dem Hersteller meines Betriebssystems traue, sonst würde ich es nicht nutzen. Aber selbst wenn man das anders sieht: so ein Repository kann man auch komplett oder teilweise spiegeln, insbesondere in Unternehmen kann das schon allein deshalb sinnvoll sein damit nicht alle Pakete n mal übertragen werden müssen. Dementsprechend hat man in der Regel auch die Auswahl zwischen mehreren Repositories im Netz. Da kann man sich dann überlegen wem man das Vertrauen schenken möchte.
Alles in allem bleibe ich bei dem was ich damals schon gesagt habe: ständig auf der Jagd nach Updates zu sein wäre mir zu stressig. Und das würde ich insbesondere nicht-computeraffinen Benutzern nicht zumuten wollen. Denkt daran wenn Eure Eltern von Euch einen Computer eingerichtet haben wollen!
Schön finde ich übrigens, dass Heise in dem Artikel auf XKCD linkt.
Skripten unter Windows
Heute habe ich jemandem über die Schulter gesehen der sich an einem Batch-Skript auf Windows versucht hat. Kein schöner Anblick. Und nein, PowerShell gab es auf dem System nicht. Um nicht schlecht davon zu träumen habe ich überlegt wie ich die Aufgabe gelöst hätte. Falls mal jemand sowas an mich heranträgt werde ich mir auf jeden Fall Busybox für Windows ansehen.
Hash Rocket
Aus verschiedenen Programmiersprachen kennt man die Notation von Hash-Arrays mittels ‚=>‘. Bislang habe ich das immer als eine Art Zeiger verstanden. Also bildlich.
Ich beschäftige mich gerade mit Puppet. Das ist zwar keine Programmiersprache, die Konfiguration sieht aber trotzdem so aus:
file {'/tmp/test1':
ensure => present,
content => "Hi.",
}
Das — übrigens sehr schön geschriebene — Learning Puppet hat mir gerade beigebracht dass man dieses ‚=>‘ als Hash Rocket bezeichnet. War mir auch neu.
Hoch bewertete Schauspieler
Vorweg: ich fühle mich Heute nicht sehr gut, könnte sein dass ich Fieber habe. Da kommt man auf die merkwürdigsten Ideen…

openDB
Vor mir liegt also eine MySQL-Datenbank in der viele Filme, deren IMDB-Bewertungen und die mitwirkenden Schauspieler gelistet sind. Und mein vollgeschnoddertes Gehirn stellt mir die Frage: welcher Schauspieler hat wohl in den bestbewerteten Filmen mitgewirkt?
Die Struktur der Datenbank ist nicht unbedingt ideal für so eine Abfrage, daher hat es fast eine halbe Stunde gedauert bis ich dieses kleine Monster hatte („Ein Kerlchen von erlesener Hässlichkeit“ hätte meine Mathelehrerin wohl dazu gesagt. ):
select count(1) filme, round(avg(ia1.attribute_val),2) durchschnitt, ia2.attribute_val schauspieler
from item_attribute ia1
join item_attribute ia2 on ia1.item_id=ia2.item_id
join item i on i.id=ia1.item_id
join item_instance ii on ia1.item_id=ii.item_id
where ia1.s_attribute_type='IMDBRATING'
and ia2.s_attribute_type='ACTORS'
group by ia2.attribute_val
having filme>=10
order by durchschnitt desc
limit 30;
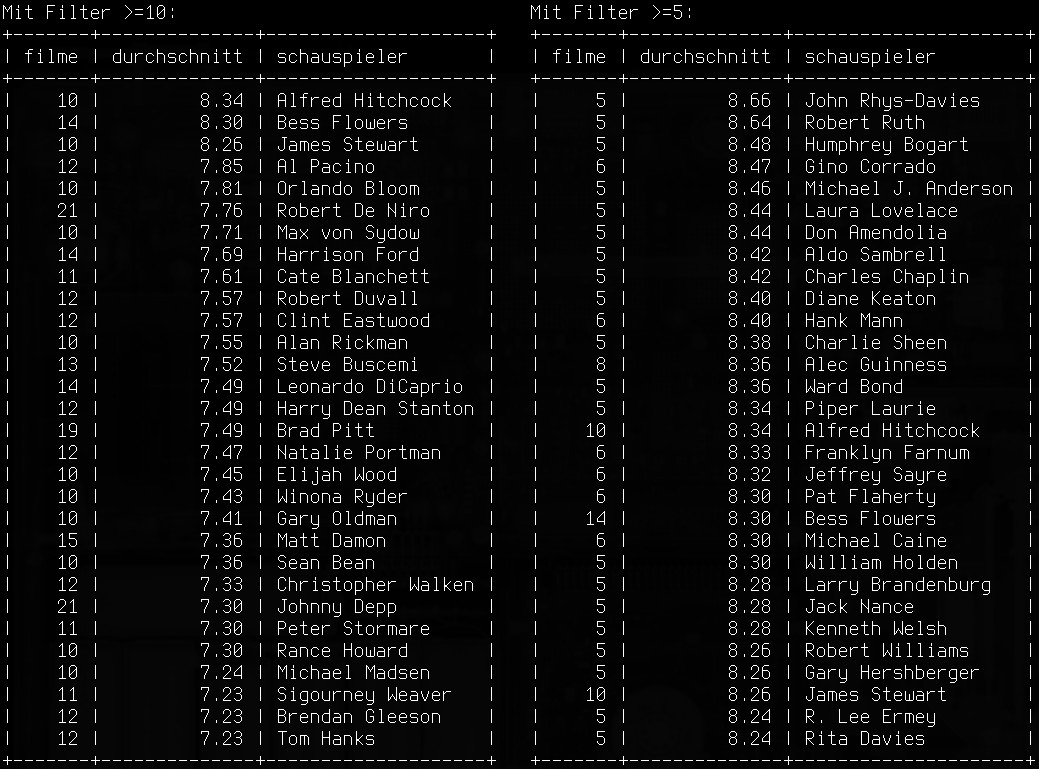
Die besten, der besten…
Das Ergebnis mit beiden Filtern ist im nebenstehenden Screenshot zu sehen. Man bedenke: Datenbasis sind ausschließlich die Filme die ich original hier habe (ja, da sind wirklich keine Kopien dabei!). Und bewertet wurde nicht die Leistung der Personen, sondern die der Filme in denen sie gespielt haben. Ich muss beispielsweise gestehen dass mir John Rhys-Davies erstmal nichts gesagt hat. Es reicht aber, dass er in zwei Indiana-Jones- und drei Herr-der-Ringe-Filmen mitgespielt hat (als Sallah bzw. Gimli), damit er die eine Liste anführt. Alfred Hitchcock war ein großartiger Regisseur, durch seine kleinen Cameo-Auftritte steht er aber auch als Schauspieler an der Spitze der Liste.
Apropos Regisseur: wenn ich nicht nach Schauspielern sondern nach Regisseuren auswerte — vielleicht ist das fairer — führt bei einem Filter von 5 Sergio Leone die Liste an, gefolgt von Akira Kurosawa und Charlie Chaplin.
Oh, und wo ich gerade dabei bin… hier nochmal eine Liste der Schauspieler von denen ich die meisten Filme habe. War dann nur noch eine Fingerübung:
Bruce Willis (38), Samuel L. Jackson (24), Robert De Niro (21), Tom Cruise (21), Johnny Depp (21), Brad Pitt (19), Morgan Freeman (16), Harvey Keitel (15), Nicole Kidman (15), Matt Damon (15), Leonardo DiCaprio (14), Harrison Ford (14), Mel Gibson (14), Bess Flowers (14), Steve Buscemi (13).
Die Reihenfolge gibt komischerweise meine persönliche Meinung von deren Können überhaupt nicht wieder… Robert De Niro, Al Pacino oder auch Sean Connery halte ich für deutlich fähiger als Bruce Willis, dabei sind die letzten beiden nicht mal in der Top15…
Naja, vielleicht sagt das ja doch alles nichts aus. Vielleicht sollte ich mir mal die Datenbasis der IMDB besorgen (ja, das geht.) und darauf Auswertungen fahren. Nicht nur auf mein eigenes Regal. Zumindest hat es mir geholfen, eine Weile nicht nur über die Schnodderei nachzudenken…
Alfresco auf Debian installieren
Login, bitte
Haken an der Sache: das ist eine Java-Anwendung, und die drückt ganz schön auf mein kleines Heimserverchen. Um es nicht zu sehr ausarten zu lassen möchte ich nach Möglichkeit kein volles KVM installieren, sondern in einem OpenVZ-Container (wir erinnern uns: ich habe Proxmox auf meinem Server installiert). Problem dabei: in OpenVZ habe ich nur 32-Bit-Gäste, und der vergleichsweise einfach zu bedienende Installer von Alfresco läuft nur auf 64 Bit.
Also zu Fuss. Und da ich zwar mehrere Anleitungen gefunden habe, keine davon aber wirklich alle meine Probleme gelöst hat, schreibe ich hier mal zusammen was ich gemacht habe. Ich installiere erstmal nur das Basispaket, Zusatzmodule kommen bei Bedarf später nach.
Noch ein Disclaimer vorweg: alles was hier steht ist gefährliches Halbwissen! Meine Erfahrungen mit Alfresco beschränken sich auf wenige Stunden Spielerei, auch Java und Tomcat sind für mich kein Heimspiel. Was ich aufgeschrieben habe hat zumindest auf den ersten Blick für mich funktioniert. Mit dem Ergebnis habe ich noch nicht viel Zeit verbracht. Es kann also durchaus sein dass ich Quatsch geschrieben habe. Falls jemandem Fehler oder Verbesserungen einfallen wäre ich sehr dankbar für einen kurzen Hinweis. Falls mir noch was auffällt werde ich einen entsprechenden Nachtrag schreiben.
- Maschine anlegen. Ich gebe erstmal nur 1,5GB RAM, dazu 5GB Festplatte.
- Debian installieren. Debian 7.0 ist mittlerweile so gut wie stabil, also gibt es direkt Wheezy. Dazu das übliche: Apt-Cache eintragen und alles erstmal aktualisieren.
- Datenbank anlegen. Ich nutze MySQL, die Datenbank liegt auf einem anderen Server. ‚
create database alfresco‚. - Benötigte Pakete installieren:
apt-get install libreoffice openjdk-7-jre imagemagick tomcat7 mysql-client libmysql-java zip‚. Die Java-Version scheint wirklich wichtig zu sein, mit Version 6 hatte ich kein Glück beim vollständigen Anlegen der Datenbank. - Die SWFTools kennt Debian zwar als Paket, hier fehlt dann allerdings das essentiell wichtige pdf2swf. Wir ziehen uns die Sourcen (Version 0.9.1, 0.9.2 bringt einen Fehler bei der Installation) und compilieren klassisch mit
./configure && make && make install. Voraussetzung hierfür:apt-get install zlib1g-dev libjpeg62-dev libgif-dev libfreetype6-dev g++ make. - Alfresco herunterladen. Wir brauchen das Paket für die manuelle Installation, aktuell also alfresco-community-4.2.c.zip.
- Den Inhalt des Paketes unter /opt/alfresco auspacken.
- Sicherstellen dass Tomcat nicht läuft, damit der uns nicht in die Quere kommt:
/etc/init.d/tomcat7 stop - Dateien und Verzeichnisse vorbereiten:
# cp -r /opt/alfresco/web-server/shared/ /var/lib/tomcat7/
# cp -r /opt/alfresco/web-server/webapps/ /var/lib/tomcat7/
# cp -r /opt/alfresco/bin/ /var/lib/tomcat7/
# ln -s ../../java/mysql-connector-java.jar /usr/share/tomcat7/lib/
# mv /var/lib/tomcat7/shared/classes/alfresco-global.properties.sample /var/lib/tomcat7/shared/classes/alfresco-global.properties
# mv /var/lib/tomcat7/shared/classes/alfresco/web-extension/share-config-custom.xml.sample /var/lib/tomcat7/shared/classes/alfresco/web-extension/share-config-custom.xml
# mkdir /opt/alfresco/alf_data
# chown -R tomcat7:tomcat7 /var/lib/tomcat7/ /opt/alfresco/alf_data/ - Konfigurationsdatei
/var/lib/tomcat7/shared/classes/alfresco-global.propertiesanpassen. Hier nur die geänderten Zeilen:
dir.root=/opt/alfresco/alf_data
db.username=alfresco
db.password=GEHEIMESPASSWORT
ooo.exe=/usr/bin/soffice
ooo.enabled=true
jodconverter.officeHome=/usr/lib/libreoffice/
jodconverter.portNumbers=8101
jodconverter.enabled=true
img.root=/usr
img.exe=/usr/bin/convert
swf.exe=/usr/local/bin/pdf2swf
db.driver=org.gjt.mm.mysql.Driver
db.url=jdbc:mysql://DATENBANKSERVER/alfresco?useUnicode=yes&characterEncoding=UTF-8 - Speichermanagement für Tomcat anpassen, in /etc/default/tomcat7 folgende Einstellungen hinzufügen:
JAVA_OPTS="${JAVA_OPTS} -XX:MaxPermSize=512m -Xms128m -Xmx768m -Dalfresco.home=/opt/alfresco -Dcom.sun.management.jmxremote" - Tomcat starten:
/etc/init.d/tomcat7 start
Danach kann man seinen Browser ganz vorsichtig auf http://SERVERNAME:8080/share oder http://SERVERNAME:8080/alfresco loslassen. Nicht vorschnell aufgeben, der erste Aufruf kann durchaus mehrere Minuten dauern. Die Zeit kann man sich zum Beispiel damit vertreiben, in der Datenbank nachzusehen ob tatsächlich die nötigen Tabellen angelegt werden. Direkt nach dem Laden der Startseite sind in der DB schon 102 Tabellen und mehrere Tausend Datensätze vorhanden.
Genau hier hat mich übrigens der Fehlerteufel eine Weile in Schach gehalten: in meinen ersten Anläufen hatte ich openjdk-6-jre installiert, so wie die meisten (zugegeben: teils alten) Howtos raten. Das führt neben einem Riesenhaufen Logs — die für einen nicht-Java-affinen Menschen erstmal nichtssagend sind — zu genau 20 Tabellen in der Datenbank, und dazu dass man unter /alfresco nur eine Fehlermeldung präsentiert bekommt. Darauf, das mal mit Java 7 zu testen muss man erstmal gestossen werden…
Wenn die Startseite (endlich!) sauber lädt kann man sich mit admin:admin anmelden und anfangen zu überlegen was man mit so einem schönen, neuen, großen Spielzeug anfangen kann… Aber das ist eine andere Geschichte, und die soll ein anderes Mal erzählt werden…
Geholfen haben mir bei der Installation hauptsächlich diese beiden Anleitungen, sowie dieser Thread im Support-Forum. Den Rest habe ich mir zusammengegoogled. Danke an alle die Ihr Wissen im Netz teilen!
Nachtrag (05.03.): Aufgrund eines Fehlers im Zusammenspiel zwischen Flash und dem Browser habe ich Flash-Upload abgeschaltet. Sonst hätte ich in der Weboberfläche keine Dateien hochladen können. Nutzen kann man Alfresco auch anders, aber wenn schon… Um abzuschalten in der Datei /var/lib/tomcat7/shared/classes/alfresco/web-extension/share-config-custom.xml den Wert adobe-flash-enabled auf false setzen und den Tomcat durchstarten.