Zwei Wollfäden, aufgenommen mit dem PhotoStepper (ein Stapel aus 60 Bildern, jeweils um 0,3mm versetzt) und einem 50 Jahre alten 85mm-Objektiv am Balgen. Keine weitere Nachbearbeitung, nur etwas zugeschnitten.
Edit: Ich hätte nicht gedacht dass ich dazu ein Statement abgeben müsste, aber da ich dazu eine Anmerkung bekommen habe: natürlich ist die Farbwahl kein Zufall. Ich denke durchgehend an die Menschen in der Ukraine, aber viel dazu sagen kann ich nicht. Es lässt mich sprachlos zurück. Vor zwei Wochen hätte ich noch gewettet dass es so einen Wahnsinn in Europa nie wieder geben wird — und natürlich gehofft dass Krieg auch in allen anderen Teilen der Welt aus der Mode kommt.
Vom beginnenden Krieg habe ich letzten Donnerstag nicht durch die Nachrichten erfahren sondern von einem Mitglied einer Chatgruppe der ich angehöre. Alex wohnt in Kiew, er schrieb morgens um halb sechs von Explosionen.
Gestern hat es die Überschrift eines Beitrags auf irgendeiner Nachrichtenseite geschafft mir Tränen in die Augen schießen zu lassen. Den Artikel habe ich nicht gelesen. Aber der Satz „Vor Abfahrt malten wir bei allen Kindern die Blutgruppe auf den Rucksack“ lässt mich nicht mehr los.
Ich kann dazu nicht viel sagen. Ich kann nur hoffen.
Eins meiner großen — wenngleich in den letzten Jahren sehr vernachlässigten — Hobbies ist die Fotografie. Mich hat immer schon die Technik gereizt, und die Möglichkeit da Grenzen auszuloten. Beispiele dafür sind der Hochgeschwindigkeits-Blitzauslöser den ich vor fast 20 Jahren gebaut habe (damals noch ohne Mikrocontroller (!)), oder mein Labor in dem ich den guten alten Kodak T-Max P 3200 weit über sein Limit gepusht habe.
Ein Thema das mich immer fasziniert hat ist Makrofotografie. Bei meiner ersten Spiegelreflexkamera — einem Erbstück von Opa, irgendwas voll-manuelles von Revueflex — hatte ich schon einen Satz Zwischenringe gefunden. Einfache, mit M42-Anschluss. Die haben mich angefixt. Nach dem Einstieg in die EOS-Welt habe ich dann einen Adapter gekauft um die Sachen auch an der neueren Kamera zu benutzen, irgendwann auf einer Fotobörse dann auch ein Balgengerät. Und noch eins.
Endgegner Tiefenschärfe
Ein Problem beim Anfertigen von Makrofotos ist, unabhängig davon mit welcher Technik man in die Extreme geht, die fehlende Tiefenschärfe. Nicht selten hat man es da mit Millimetern oder auch nur Bruchteilen davon zu tun. „Zu meiner Zeit“, also in der analogen Fotowelt, musste man sich weitestgehend damit begnügen. Heutzutage wird aber digital geschossen. So ist irgendwann jemand auf die Idee des Focus Stacking gekommen: man macht nicht nur ein Bild, sondern einen ganzen Stapel von Bildern. Jeweils mit dem Fokus in einer anderen Ebene. Diesen Stapel lädt man dann in eine Bildbearbeitung und bastelt so lange daran herum bis man nur noch die scharf abgebildeten Teile hat — und somit ein Bild mit einer deutlich verlängerten Tiefenschärfe.
Natürlich will man dafür nicht einen halben Tag in Gimp rumklicken, deshalb haben findige Entwickler Programme geschrieben die den Part übernehmen. Kommerzielle gibt es natürlich, ich habe mich aber an Open Source gehalten.
Stapelfotografie per Arduino
PhotoStepper
Was ich mir gebaut habe ist nicht neu. Man kann solche Geräte von verschiedenen Herstellern kaufen, es gibt auch eine ganze Reihe von gut dokumentierten Bastelprojekten. Teilweise sogar mit praktisch der gleichen Hardware die ich benutzt habe. Warum ich das trotzdem selbst gemacht habe? Einfach weil ich wissen wollte ob ich es kann.
Ich habe also einen alten Arduino Uno aus der Bastelkiste gefischt, dazu ein LCD-Keypad-Shield das ich mal aufs Geratewohl gekauft habe. Mit einem Schrittmotortreiber (A4988) und einem Motor den ich hier noch von einem anderen Projekt hatte konnte ich dann schon ausprobieren wie sowas zusammenspielt. Vermutlich hätte ich den Arduino auch direkt an den Kabelauslöser-Anschluss meiner Kamera anschliessen können, das war mir aber in Anbetracht der 12V Versorgungsspannung zu aufregend. Also habe ich das durch zwei Optokoppler (PC817) gemacht.
Linearantrieb
Die prototypischen Tests haben gut funktioniert, also habe ich ein Gehäuse gedruckt und mich nach passender Mechanik umgesehen. Einen Linearantrieb samt Motor konnte ich praktisch als Schnäppchen ergattern. Dazu eine Schiene für die Befestigung auf dem Stativ und eine Klemmplatte um die Kamera auf dem Schlitten anzubringen. Da ich eher Schreiner bin als Mechaniker sind die Verbindungen zwischen den Teilen rustikal in Eiche gehalten.
Die Teile sind genau wie mein Stativ Arca-Swiss kompatibel (noch so ein Begriff den es „zu meiner Zeit“ noch nicht gab), so kann die Grundplatte an der Kamera bleiben und alles ist schnell und stabil zusammengesetzt.
Fotosession
Aufnahme-Setup, noch ohne den Blitz
Mein erstes Motiv — ein ziemlich schmutziges Centstück — war nicht originell, und der Aufbau halbwegs krude. Kamera mit Balgen und einer 58mm-Optik aus dem Nachlass meines Opas auf das Gerät, per Funk einen diffusen Blitz auf das „Model“.
Ich habe erst den Bildausschnitt eingestellt und grob auf die Münze scharfgestellt. Dann Kamera und Blitz manuell eingestellt und die Belichtung geregelt. Bis hierher alles wie anno dazumal.
Dann kam der Neubau zum Zug: ich habe die Kamera ein Stück vorgefahren, so dass die Schärfeebene deutlich hinter dem Geldstück war. Dann am Gerät eingestellt dass ich 30 Bilder schießen will, jeweils im Abstand von 1mm. Somit habe ich 3cm abgedeckt — genug für die Münze, aber wenn man sich die fertige Aufnahme ansieht nicht genug um bis an den oberen Bildrand scharf zu bleiben. Schade, aber ist ja auch nur ein Test.
Centstück, 30 Fokusebenen
Eine knappe Minute — und einen Freudentanz hinter der Kamera — später sind 30 Bilder im Kasten.
Die ziehe ich mir auf den Computer und bearbeite sie mit zwei Tools: align_image_stack aus dem Hugin-Paket stellt noch einmal sicher dass alle Bilder gleich ausgerichtet sind, außerdem sorgt es dafür dass die Größen angepasst werden. Die Kamera fährt währen den Aufnahmen vom Motiv weg, dementsprechend wird selbiges immer kleiner. Das wäre Gift für das folgende Stacking.
Das übernimmt dann enfuse aus dem Enblend-Projekt. Und das erstaunlich gut, wie ich finde. Nicht perfekt: oben im Bild sind noch ein paar Artefakte von der Verarbeitung. Aber wirklich erstaunlich gut. Insbesondere für einen ersten Versuch.
„Ich brauche mehr Details…“
Ich habe das komplette Projekt, samt der Quelltexte und einer Beschreibung der Elektronik, veröffentlicht.
Wer mag kann sich alles im Detail ansehen, für Verbesserungen bin ich immer offen.
Und jetzt?
Ehrlich gesagt weiß ich noch nicht was ich mit dem Ding fotografieren sollte. Ideen habe ich ein paar, aber mir ging es hauptsächlich darum sowas zu bauen. Erledigt. Abgehakt.
Dass es sich hier nicht um eine bahnbrechende Erfindung handelt ist mir auch klar. Ich weiß dass es einige moderne Kameras gibt die eine Funktion zum Focus Stacking schon eingebaut haben. Wer sowas unbedingt braucht wird wahrscheinlich zu so einem Modell greifen. Mein „Oldie“ von 2009 kann das nur mit diesem Hilfsmittel.
Da ich mit dem Gerät ganz allgemein nur einen Schrittmotor und die Kamera steuere kann ich mir vorstellen das mit einem Drehteller zu betreiben. So könnte ich Dinge kontrolliert von allen Seiten ablichten. Wofür weiß ich noch nicht, aber vielleicht entwickelt sich das ja nochmal irgendwann in Richtung Photogrammetrie, also vielleicht ein Hilfsmittel zum Erstellen von 3D-Modellen. Mal sehen…
Als ich klein war habe ich mal als Belohnung für Tapferkeit im Krankenhaus — Blinddarm-OP — einen großen Wunsch erfüllt bekommen: ein Playmobil Piratenschiff. Das dürfte ziemlich genau dieses hier gewesen sein.
Das Ding war nicht billig. Naja, es wird um die 100 Mark gekostet haben. Aber das war für meine Eltern zu der Zeit eine Menge Geld. Geschenke in der Größenordnung waren selbst zu Weihnachten nicht selbstverständlich. Dementsprechend glücklich war ich auch damit. Ehrlich gesagt kann ich heutzutage nicht mehr ganz nachvollziehen worin der Spaß bei Playmobil besteht. Da habe ich mich wohl eher zum Lego-Typen entwickelt.
Oh, einen großartigen Einsatz von Playmobilfiguren habe ich doch in jüngerer Zeit gesehen: den ausgezeichneten Youtube-Kanal Sommers Weltliteratur to go. Da kann man sich playmobilisierte Kurzfassungen bekannter Bücher ansehen, von der Bibel über Faust und Clockwork Orange bis Harry Potter.
Zurück zum Thema: es wird dieses Jahr ein neues Playmobil-Schiff geben. Nein, nicht für mich. Selbst wenn der Anschaffungswiderstand nicht bei voraussichtlich dem zehnfachen meines alten Piratenschiffs liegen würde: die NCC-1701-Puppenstube ist einen Meter lang, und ich würde wohl kaum eine Genehmigung bekommen sowas in der Wohnung aufzustellen.
Davon abgesehen ist das die originale Enterprise, also Kirks Schiff. Um Scotty zu zitieren: „NCC-1701. No bloody A, B, C, or D.“ Wenn die aber irgendwann mit Picards NCC-1701D um die Ecke kommen kann ich für nichts garantieren…
Nein, ich schreibe jetzt nicht jeden Tag was neues auf die Seite. Aber nachdem ich gestern die große Pause abgebrochen habe bin ich heute mal neugierig in die Aufrufstatistiken gegangen. Mal nachsehen ob das hier tatsächlich noch gefunden wird.
Das Statistik-Tool meiner Wahl — Matomo — hat einen SEO-Block, und der sagt unter anderem „Domain Age: 20 years 71 days“. Wie immer bei SEO ist das Kaffeesatzleserei, aber ich habe gerade mal nachgesehen: angemeldet habe ich die Domain am 07.11.2000, das wirkliche Jubiläum wäre also vor etwas mehr als einem halben Jahr gewesen.
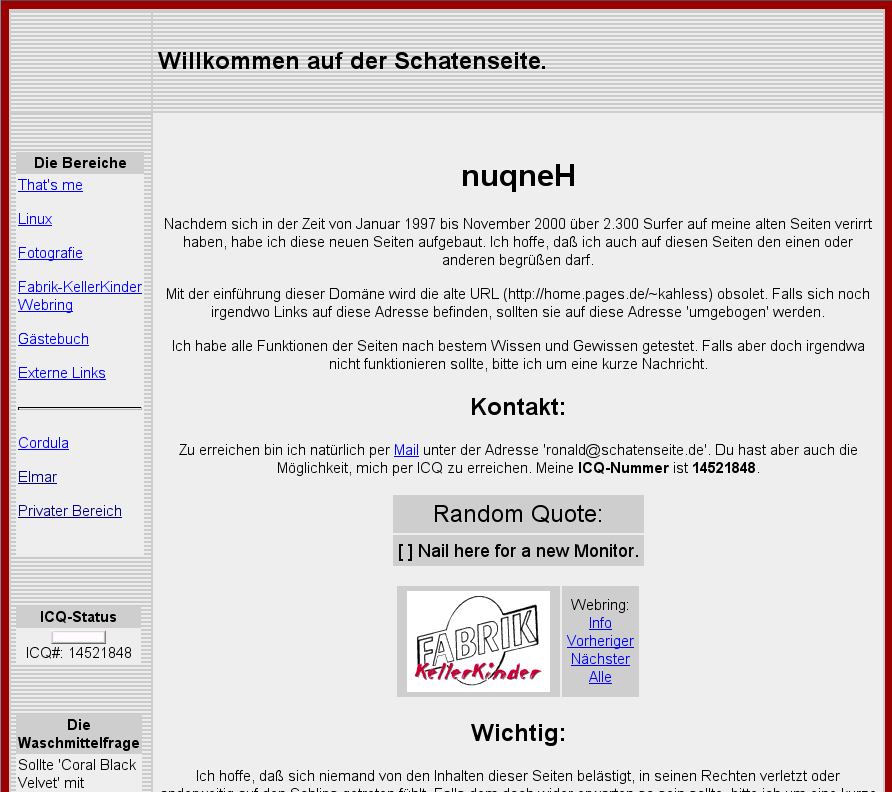
Die Geschichte der Seite ist auf der Meta-Seite nachzulesen. Daher stammt auch der Screenshot, der zeigt die Seite wie sie vor 20 Jahren ausgesehen hat. Über den Quote in der Mitte musste ich wieder schmunzeln, ich bin also immer noch leicht zu amüsieren. Was es mit der Waschmittelfrage unten links auf sich hatte fiel mir beim besten Willen nicht mehr ein, aber… das Internet vergisst nicht…
Die Liste gibt es am Ende des Artikels als PDF zum Ausdrucken
Nach langer Zeit der erste richtige Artikel. Und es geht um ein analoges Spiel namens MicroMacro: Crime City.
Ich weiß nicht ob man das als Brettspiel bezeichnen kann, ein Spielbrett gibt es nämlich nicht. Stattdessen ein riesengroßes monochromes Wimmelbild. Gezeigt wird eine Stadt in der jede Menge los ist. Wohnen möchte man da nicht unbedingt, bei genauem Hinsehen sieht man viele Verbrechen, vom Diebstahl bis zum Mord. Und diese Verbrechen kann man tatsächlich anhand des Bildes aufklären.
Wer sich das nicht vorstellen kann klickt auf diesen Link, da gibt es einen Demo-Fall den man online spielen kann. Alternativ sieht man sich die Schachtel genau an, auch da kann man den ersten Fall schon lösen ohne das Spiel auszupacken.
Zusammen mit meinen Töchtern habe ich schon mehr als die Hälfte der Fälle aufgeklärt, wir hatten eine Menge Spaß mit diesem wirklich völlig neuen Spielkonzept. Ich freue mich auf den Nachfolger der für den Herbst angekündigt ist, und ich wünsche dem Verlag viel Erfolg bei der Verleihung des Preises „Spiel des Jahres“. Nominiert ist das Spiel schon mal.
Kommen wir zum Grund für diesen Artikel: wir besitzen die erste Auflage des Spiels. Und ich vermisse ein Feature das in einer neueren Auflage dazu gekommen ist: Triggerwarnungen. Im Spiel sind 16 Fälle enthalten, einige davon behandeln Themen mit denen man jüngere Kinder vielleicht nicht unvorbereitet konfrontieren möchte. In der Neuauflage hat jeder Fall eine Kennzeichnung die aussagt ob man sich den Fall vielleicht erstmal selbst ansieht bevor man seine Kinder ran lässt. Im Spiel gibt es keine wirklich expliziten Darstellungen, das ist meiner Meinung nach absolut tauglich für achtjährige (so wird es auch auf der Schachtel empfohlen). Aber mit Mord und Totschlag kann man vielleicht doch den Spieleabend in eine unerwünschte Richtung lenken…
Der Verlag war so freundlich, mir eine Datei mit den Deckblättern der neuen Version zur Verfügung zu stellen. Das ist nett, lässt sich aber leider nur umständlich in das Spiel integrieren. Also habe ich die Datei mit einer Idee von BGG kombiniert und einmal durch Inkscape gezogen. Herausgekommen ist eine A4-Seite die man ausdrucken und in die Schachtel legen kann. Man sieht alle Fälle und deren Schwierigkeitsgrad, zusätzlich die Einschätzung der Redaktion bezüglich der Inhalte. Neben jedem Fall ist ein Kästchen in dem man dann auch einfach abhaken kann ob der schon gelöst wurde oder noch nicht.
Ich glaube das könnten auch andere — insbesondere Eltern — brauchen, also habe ich den Verlag um Erlaubnis gebeten die Datei hier anbieten zu dürfen. Hier ist sie, viel Spaß damit:
Nein, die Schatenseite ist nicht tot. Es geht weiter, auch wieder mit Bastelprojekten und dem ganzen Kram der hier sonst stattfindet.
Aber noch nicht heute.
Heute muss ich mir erstmal Luft machen. Hier kommt nichts neues, das wurde alles schon von vielen Leuten geschrieben. Trotzdem muss es raus. Schon allein damit ich das bei Gelegenheit selbst mal nachlesen kann.
Hier stand ursprünglich ein langer Entwurf für diesen Post. Sehr lang. Wall of Text. Eine Beschreibung meines Umfelds, meine Sicht auf Corona-Maßnahmen und deren Lockerungen und was das alles mit mir macht. WordPress hat angezeigt dass da fast 1500 Worte zusammengekomen sind. Die Version habe ich verworfen und durch eine Kurzfassung ersetzt. Die wieder erweitert und dann doch wieder gekippt. Jetzt also nach reiflicher Überlegung die „tattooable version“, zu der kann ich stehen:
In der fünften Klasse wird zur Zeit im Matheunterricht das „Zweiersystem“ erklärt, Leser dieses Blogs werden das eher als Binärzahlen kennen.
Meine Lieblings-Fünftklässlerin hat mich um Hilfe gebeten, und natürlich tut man was man kann. Was kann man tun wenn man ein Geek mit einem Lasercutter ist? Man baut ein Zählwerk:
Binärzähler, Laser in Holz
Die Idee dazu kam von Twitter, das Video da ist mir vor längerer Zeit mal aufgefallen. Der Macher hat die Dateien offenbar doch nicht mehr veröffentlicht, also musste FreeCAD ran.
Ich bin echt zufrieden mit dem Ergebnis, offenbar hat es auch wirklich beim Verständnis geholfen wenn man physisch sieht wie bei einem Überschlag — und das ist hier wörtlich zu nehmen — die jeweils nächste Stelle ins Spiel kommt.
Falls noch jemand Interesse an dem Ding hat, hier sind die Dateien (geplant für 4mm Material):
Ich beharre auf meiner Ansicht: „Morgen“ ist, nachdem ich geschlafen habe.
Dementsprechend ist „Heute“ noch der zweite Weihnachtstag, und nachdem ich den Blog am selbigen in 2004 gestartet habe ist es der fünfzehnte Jahrestag.
Es ist viel passiert, in der Zeit. Das meiste hat natürlich nicht hier im Blog stattgefunden. Nicht mal das meiste der für mich bedeutsamen Ereignisse. Vor 15 Jahren war ich noch Junggeselle, aber schon mit meiner späteren Frau liiert. Ich betrachte mich mittlerweile als glücklich verheiratet, und als stolzen Familienvater. Über die Jahre habe ich mich darüber hinaus mit einigen Sachen beschäftigt. Hobbies die hier stattgefunden haben (Was mit Elektronik), Hobbies die privat stattgefunden haben (Was mit Brettspielen) und — das hätte ich damals kategorisch ausgeschlossen — sogar ein Hobby das es zu einem kleinen Nebenerwerb in Form eines Unternehmens gebracht hat (Was mit Holz).
Wie auch immer: das Leben geht weiter, und es hat sicher — auch wenn mir das eigentlich gegen den Strich geht — noch ein paar Überraschungen parat. Und auch wenn ich den Blog jetzt anders bespiele als früher geht es auch hier weiter. Immer wenn ich der Ansicht bin dass es was zu schreiben gibt, aber, und das möchte ich betonen: nicht öfter.
Ich habe auch schon wieder was interessantes zu zeigen, aber das seht Ihr erst nachdem es mein Patenkind sieht. Aus Gründen.
Ach ja: im Titel steht „15 Jahre (netto?)“. Den Blog gibt es seit 15 Jahren, ununterbrochen. Aber ein fünfzehnjähriges Jubiläum ist in meinem Hirn fest mit der besten Band der Welt und ihrem „15 Jahre Netto“ Konzert verbunden. Ich kann (und will) nicht sagen wie oft ich die live gesehen habe, nur soviel: ich freue mich auf 2020.
Der Satz mit dem ich vor fünf Jahren abgeschlossen habe behält seine Gültigkeit: vielen Dank für Eure Aufmerksamkeit!
Wer öfter mal was in der Shell macht kennt vermutlich das Kommando find. Damit kann man sehr flexibel Dateien oder Verzeichnisse auf der Festplatte suchen. So findet man zum Beispiel alle Dateien die älter sind als 100 Tage:
1
find.-typef-mtime+100
Um die Größen aller Dateien zu bekommen kann man find bitten für jede Datei ein du (Disk Usage) auszuführen:
1
find.-typef-mtime+100-execdu-b{}\;
Kann man machen, aber das bedeutet dass find für jede einzelne Datei ein Kommando startet. Jetzt braucht du nicht sehr lange für die Ausführung, aber wenn man stattdessen beispielsweise jeweils ein Perl-Skript starten muss wirkt sich das sehr negativ aus.
Wenn man nur wenige Fundstellen erwartet kann man folgendes machen:
1
du-b$(find.-typef-mtime+100)
So wird vor der Ausführung von du die Klammer expandiert und durch die Ausgabe von find ersetzt. Das hat aber einen bedeutenden Haken: wenn sehr viele Dateien gefunden werden wird die Kommandozeile zu lang die man durch die Expansion erhält („-bash: /usr/bin/du: Argument list too long“) — Zeilen dürfen nicht beliebig lang werden (man findet die zulässige Länge mit getconf ARG_MAX, muss von der Zahl aber noch die Größe der Umgebungsvariablen abziehen).
Um das zu umgehen ruft man klassisch xargs zur Hilfe. Das sieht dann so aus:
1
find.-typef-mtime+100-print0|xargs-0du-b
Jetzt findet find alle gesuchten Dateien und gibt deren Namen nullterminiert nach STDOUT. Von da liest xargs ein und baut eine Kommandozeile mit du -b. In diese Zeile werden so viele der eingegebenen Strings reingepackt wie möglich bevor du ausgeführt wird.
Aber find braucht offenbar kein xargs
Man kommt — und das weiss ich erst neuerdings — auf das gleiche Ergebnis wenn man in find statt des Semikolons ein Pluszeichen benutzt:
1
find.-typef-mtime+100-execdu-b{}+
Keine Ahnung wie das bislang an mir vorübergehen konnte, das macht einiges eleganter.
Wie komme ich jetzt an die Summe der Fundstellen?
Wenn man folgendes schreibt berechnet du für jeden Aufruf eine Summe, mit dem grep kann man sich die ansehen:
1
find.-typef-mtime+100-execdu-bc{}+|grep total
Bei vielen Dateien wird du mehrfach aufgerufen, man bekommt also mehrere Summen. In meinem Beispiel finde ich gut 45000 Dateien, find ruft dafür 19 Mal du auf, grep gibt mir also 19 Zeilen mit jeweils einer ziemlich großen Zahl. Die gilt es aufzusummieren, das geht am einfachsten mit awk:
1
find.-typef-mtime+100-execdu-bc{}+|awk'/total/{ total += $1 }; END { print total }'
Jetzt bekomme ich nur noch eine sehr große und sehr unleserliche Summe, die gibt mir die Summe der Größe aller gefundenen Dateien. Die kann awk mir in GB umrechnen:
1
find.-typef-mtime+100-execdu-bc{}+|awk'/total/{ total += $1 }; END { print total / (2**(30)) " GB" }'
Somit habe ich einen leserlichen Wert, damit kann ich arbeiten.
Wenn es einen einfacheren Weg zum Ziel gibt: ich bin immer für Vorschläge offen!
Ich gestehe: ich bin sowohl bei Amazon als auch bei eBay als Kunde registriert. Mea Culpa.
Vor knapp zwei Wochen habe ich einen Brief von Amazon bekommen, eine Zahlungsaufforderung. Da war die Rede von einem Monatsbeitrag für August. Da sind offenbar 29,99 Euro offen, plus 2,50 Euro für den Verzug. Was gekauft wurde stand da nicht, nur eine lange Zahl als Verwendungszweck.
Ich habe schon länger nichts mehr per Amazon gekauft, also habe ich per eMail eine Rückfrage gestellt. Mir wurde nur mit einem Textbaustein geantwortet, unter anderem stand da dass man sich den Fall ansehen und mich nochmal kontaktieren wollte. Zumindest letzteres ist nicht passiert. Bis Gestern ein zweiter Brief kam. Das gleiche, nur diesmal mit 5 Euro Verzugspauschale.
Also habe ich da angerufen. Nach einigem hin und her habe ich erfahren dass zwar mein Name und meine Postadresse stimmten, dass aber jemand mit einer anderen Mailadresse was bestellt hat. Die freundlichen Leute an der Hotline konnten mir auch sagen an welchem Tag die Bestellung getätigt wurde und was bestellt wurde: ein Brettspiel namens Azul. Ich war verunsichert. Das Spiel habe ich etwa um die Zeit gekauft, aber bei Amazon?
Eine Suche in meinen Mails hat ergeben dass ich das Spiel tatsächlich an dem Tag gekauft habe. Aber nicht bei Amazon, sondern bei eBay. Zu einem sehr guten Preis. Der war so gut dass ich erst überlegt habe ob das ein China-Klon sein könnte (ja, es gibt tatsächlich gefälschte Brettspiele), aber der Absendername und die Formulierung des Angebots sahen nicht danach aus. Der Anbieter hatte erst zwei Bewertungen. Das habe ich schon einige Male gesehen, dass Neulinge da sehr guenstig anbieten — vermutlich weil Käufer bei gleichem Preis lieber bei einem etablierten Verkäufer zuschlagen. Also: gekauft, per PayPal bezahlt, ein paar Tage später in Empfang genommen, ein paar Mal gespielt und im Regal verschwinden lassen.
Offenbar hat sich jemand bei eBay angemeldet, günstig Dinge verkauft, Geld und Empfängeradressen in Empfang genommen, dann Fake-Konten bei Amazon eingerichtet und die Ware per Monatsabrechnung an die Empfänger schicken lassen. Das fällt erst nach mehr als zwei Monaten auf, mittlerweile ist das Konto bei eBay gelöscht. Der Betrüger hat in meinem Fall etwa 20 Euro kassiert, und Amazon schickt die Rechnung an mich.
Da muss man erstmal drauf kommen. Ich würde auch eigentlich nicht damit rechnen dass Amazon frische Kunden auf Rechnung beliefert (das ist ja die „Monatsabrechnung“ wenn ich das richtig verstehe). Aber offenbar klappt die Masche…
Bin gespannt wie es damit jetzt weitergeht… ich werde mich wohl an die Polizei wenden müssen, mal fragen ob die mir zu einer Anzeige raten…
Diese Seite benutzt Cookies. Weiternutzung bedeutet Einverständnis.Ok


 English preferred?
English preferred?