
Gruselige Benutzeroberfläche
Ideal fände ich eine Lösung bei der ich nur noch ISO-Files auf den Stick legen muss, meinetwegen noch mit einem Skript das die ISOs dann beim Bootloader anmeldet. So etwas scheint es aber nicht zu geben, und das scheint mit den gängigen Bootloadern auch nicht ohne weiteres möglich zu sein.
Jetzt habe ich mir aber ein Programm angesehen das der Lösung zumindest nahe kommt: mit Multisystem kann man sich einen Stick erstellen von dem mehrere Systeme gebooted werden können.
Größter Haken beim Bau des individuellen Sticks ist dabei die Benutzeroberfläche. Von weitem sieht die zwar nett aus, damit zu arbeiten ist aber wirklich eine Herausforderung. Und damit meine ich nicht dass es eine steile Lernkurve gibt weil das Programm komplex ist, sondern schlicht weil die Oberfläche nichts taugt. Dass man die Größe der meisten Fenster nicht verändern kann ist dabei das kleinste Übel…
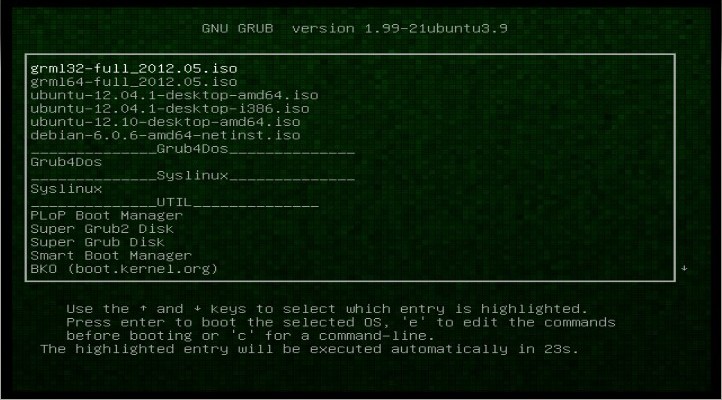
Das Ergebnis zählt
Multisystem ‚weiß‘ wie es die einzelnen ISOs behandeln muss um sie mit einem zentralen Bootloader starten zu können. Dazu ist für jedes unterstützte ISO eine Konfiguration hinterlegt, man kann dem Programm also auch nicht beliebige Systeme vor werfen. Die Ubuntu-Images liegen jetzt einfach als ISO auf dem Stick, ich weiss nicht ob ich die einfach austauschen könnte. Grml wird wie ein ‚richtiges‘ Debian behandelt und komplett ausgepackt auf den Stick gelegt. Der Traum vom Stick mit mehreren bootfähigen ISOs ist also immer noch nicht erfüllt.
Alternativ habe ich mir übrigens auch MultiCD angesehen, aber nicht wirklich ausprobiert. Wenn ich das richtig verstehe kann man damit nur CDs oder DVDs bauen, keine Sticks.
Falls doch noch jemand eine Idee hat wie man den Stick so bestücken kann wie ich mir das vorgestellt hatte: immer her damit!



